Kundera Was Right About AI

“There is a secret bond between slowness and memory, between speed and forgetting. A man is walking down the street. At a certain moment, he tries to recall something, but the recollection escapes him. Automatically, he slows down. […] The degree of slowness is directly proportional to the intensity of memory; the degree of speed is directly proportional to the intensity of forgetting.” — Milan Kundera, Slowness1
In a previous post I argued that AI has decoupled doing from learning. This one is about a related but older problem. Speed does not merely prevent memory from forming. Speed actively erases it. And this was true long before AI.
I. Kundera’s walking man#
Kundera’s image is worth sitting with. A man walks down the street. He tries to remember something. Without deciding to, he slows down. His body knows what his mind has not yet admitted: memory needs time to surface. Conversely, a man trying to forget something unpleasant speeds up, almost running, as if he could outpace the thing by pure velocity.
Kundera calls it “existential mathematics.” Slowness is proportional to memory. Speed is proportional to forgetting.
I used to read this as a poetic flourish. I now read it as a description of how my brain actually works — and, more uncomfortably, as a description of how my working life has been reorganized around forgetting.
II. Pen and paper#
For years I tried to be a digital note-taker. Every app, every system. Obsidian. Notion. Zeitgeist/zk in a Jujutsu/Git repo, WebDAV folder, etc. Some of them were very good. None of them stuck. Every few months I would drift back to a physical notebook and a pen, feel guilty about being a Luddite, and resolve to try again with the next app.
I used to explain this to myself in terms of format. I have a spatial memory — I remember where things are on a page. Digital notes have no geography. A physical notebook has. That was my theory. It is not wrong, exactly, but it is not what is actually going on.
What is actually going on is speed.

When I type, I produce words at roughly the rate I think them. Sometimes faster. The backspace key is right there. Cut, paste, rephrase, delete, move the paragraph — all free, all instant. My hands keep up with my brain, and when my brain stumbles, the tools let me edit my way around the stumble without ever confronting it.
When I write by hand, none of this is true. I write slower than I think. I cannot backspace. I cannot cut and paste. If I choose the wrong word, I am stuck with the wrong word, or I have to cross it out and live with the scar on the page. Sometimes I turn that mistake into a small art piece, slowing my train of thought even more. I can mix and match words with sketches, bullets, and colors, deliberately adding delay and slowness to the process. This means I choose the word more carefully in the first place. The friction moves upstream — from editing to composing. I think before I write, because the cost of writing wrong is higher.
And afterwards, I remember what I wrote. Not all of it. But far, far more than I ever remembered from typing.
There is neuroscience behind this. EEG studies show that writing by hand activates broader, more synchronized brain networks than typing does, in ways associated with learning and memory consolidation2. A recent review in Life puts it plainly: the slower pace of handwriting gives the brain more time to process and synthesize, while typing speed favors fast idea generation but less reflective processing3. I find this reassuring but not essential to the argument. Even without the neuroscience, Kundera’s equation explains what I experience. Handwriting forces slowness. Slowness produces memory. The notebook is not a better format. It is a slower format. That is the whole trick.
A caveat before this turns into a sermon about stationery. The pen is not always the right tool. For transactional work — a known problem, a familiar task — I reach for the fastest tool available and I do not need to remember anything, because the knowledge is already there. Speed is correct for the transactional. The pen is for the generative: figuring out what I think, sketching an architecture I have not built before, reasoning through a decision with consequences. And even then it is only the first stage — paper is not shareable, not editable, not linkable in a PR. I think it through on paper, then port to Excalidraw or a shared doc the moment the thinking is done. The pen is a thinking instrument, not a communication one.
Every modern tool is, among other things, a speed multiplier. Autocomplete is faster than typing. Typing is faster than handwriting. AI-generated prose is faster than autocomplete. Each step up the ladder, we gain throughput and lose retention, and we almost never notice the loss because the output keeps looking better. The skill is knowing which rung to stand on for which task — and not drifting, by default, to the top.
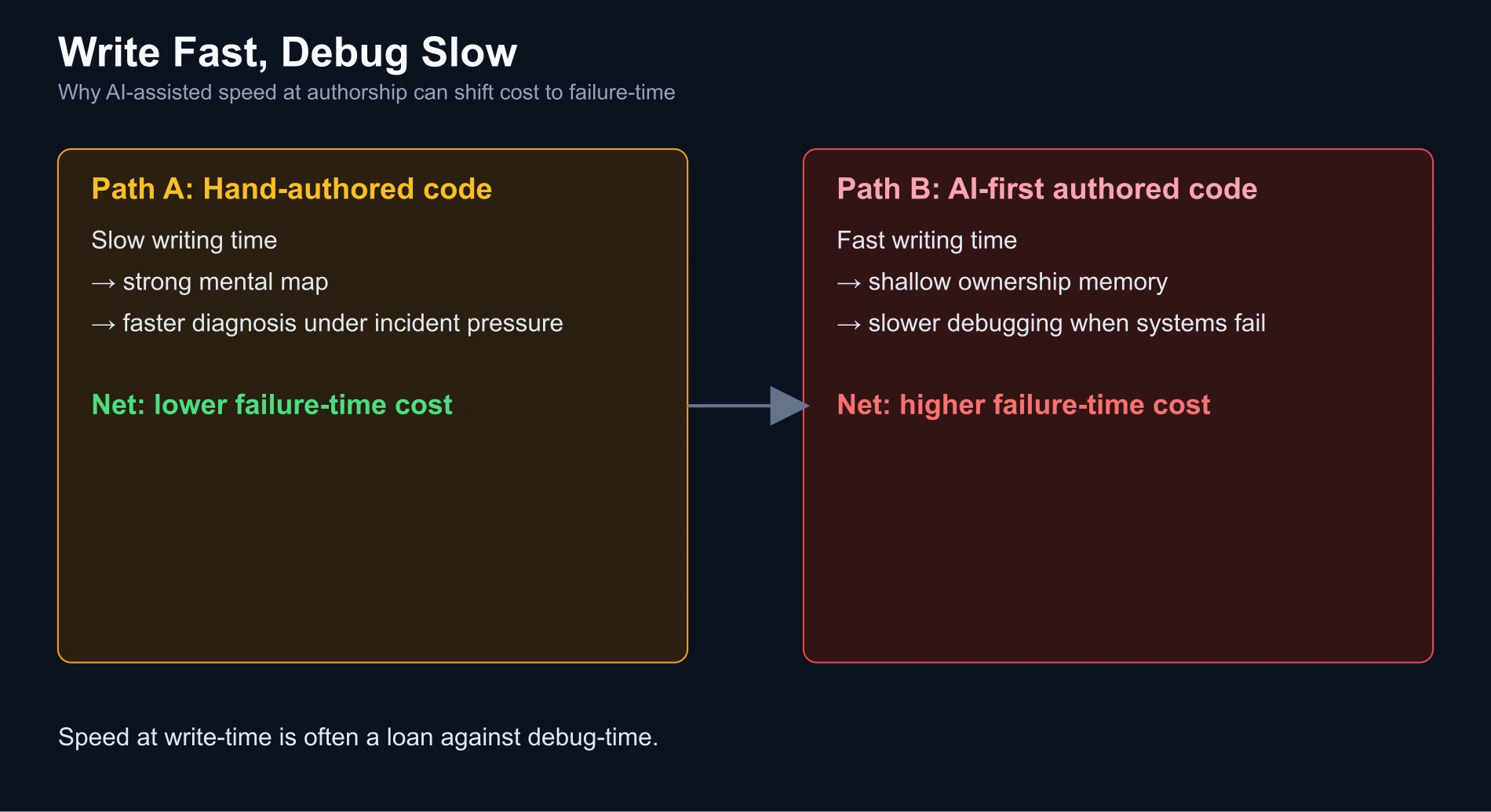
III. Code I never wrote#
Last month I had to fix a bug in production. The feature was mine — my commit, my service, my name at the top of the file. I had shipped it a few weeks before with AI assistance. Fast. Smooth. Tests passed. Deployed.
Fixing the bug took hours. Not because it was an especially hard bug. Because I was an archaeologist in my own repository.
I read functions I had signed off on and did not recognize. I traced a code path I had no memory of designing. I reached for mental models that were not there, because I had never actually built them — I had reviewed output and approved it. Review creates a thin, shallow layer of memory. It does not create the deep spatial map you get from having written the thing yourself, line by line, decision by decision, wrong turn by wrong turn.
Writing code by hand is slow. Debugging code you wrote by hand is fast, because your mind has already been through every room in the house. Writing code with AI is fast. Debugging code you shipped with AI is slow, because you are entering the house for the first time. The total work is conserved. It just got moved — from the moment of authorship to the moment of failure. And the moment of failure is almost always more expensive: production, on-call, a customer waiting.
Speed at write-time is a loan against debug-time, at a punitive interest rate.
Speed at write-time is like starting a brand-new project with months of tech debt: it drastically increases operating and maintenance costs.
IV. What I remember is what resisted me#
If I try to list everything I shipped last quarter, I cannot. I know intellectually that it was a lot. I can go look at my Jujutsu/Git commits. But in terms of lived memory — the kind I could reconstruct from first principles, the kind that shapes my judgment next time — almost all of it is gone.
What remains, vividly, is the week I spent unifying auth across a cluster.
The setup, roughly: a normal web frontend, a backend API, and a separate app streaming video through a MediaMTX server over WebRTC. Authentik in front, Traefik routing, Flux reconciling the whole thing from Jujutsu/Git. One user. One login. That last part is where it got hard.
MediaMTX is a WebRTC server. WebRTC is not HTTP in the way anything else is — the signaling is HTTP, but the media flows over UDP, and MediaMTX has no real hook for session-cookie or OIDC-style auth. The maintainers themselves recommend handling auth with a reverse proxy in front of it. Which pointed at the obvious shortcut: drop in a dedicated auth proxy, oauth2-proxy or similar, in front of MediaMTX. One more container, one more config file, done by lunch.
I fought hard not to take it. This is a small, self-hosted setup, and I was optimizing for simplicity, scalability, and cost at once. I already had coturn running for TURN relay, and a UDP port mapped per WebRTC client at the network edge. Every additional service here is not an abstraction — it is a real container, a real process to monitor, a real secret to rotate, a real line in someone’s mental model. Complexity at this scale is a tax you pay forever, on every deploy, every debug, every onboarding. Easy to add, almost impossible to remove.
So the auth had to happen at the edge I already had: Traefik intercepts the WebRTC signaling request, calls the Authentik outpost, and only lets the handshake proceed on an allow. Which meant the other apps had to play along too. If the web app did backend auth and the video app did edge auth, the user would have two logins. So the whole cluster had to unify on the mechanism that worked for the constrained case: forward auth at the edge, one Authentik session cookie scoped to the parent domain, Traefik forwarding X-authentik-* headers everywhere. The protocol two layers below the auth code had forced the architecture for everything above it. The AI did not point this out. It could not; it had no idea MediaMTX was in the picture until I told it, and even then it treated the constraint as a detail rather than the thing setting the shape of the whole system.
And underneath all of that, a second problem I did not discover until I had wasted an afternoon: my changes were not actually being applied. Flux was silently wedged. A missing sealed secret in a completely unrelated deployment — different namespace, different service — had blocked the whole kustomization. I was pushing config to Jujutsu/Git, waiting for Authentik to update, and watching nothing happen. The AI confidently diagnosed this as an Authentik configuration problem and produced three more wrong answers. It could not see my cluster. It could only see what I pasted, and I was pasting the wrong layer of the stack.
So I did the only thing left to do: I slowed down.
I started at the bottom. flux get kustomizations, find the failure, fix the sealed secret, reconciliation resumes. Check the Authentik worker. Check the outpost pod. Only then draw the request flow on paper and walk it with curl -v until every arrow made sense.
I remember all of it. I remember why the architecture had to be edge auth, why adding a second proxy would have been a mistake, how the cookie had to be scoped, and the rule I wrote for myself afterwards: before debugging any symptom, verify every reconciler in the stack is actually running. None of this was in my head three weeks before. All of it is there now, and I expect it to remain.
I used to tell myself a story about this kind of episode: struggle makes you learn. Pain is the teacher. There is research to back it up — we encode negative events more deeply than positive ones4. But I now think struggle is the wrong word. Struggle is not the mechanism. Struggle is the symptom of the mechanism. The mechanism is slowness. The MediaMTX constraint did not hurt. It simply refused to let me go fast, and that refusal is why I remember the whole thing.
The bad Authentik week was the week I could not go fast. That is the only reason I remember it.
V. The same equation, three times#
Pen and paper. Handwritten code. The auth unification. These look like three different stories — about stationery, about AI, about systems integration. They are the same story.
In each case, a tool (keyboard, AI assistant, AI assistant again) offered to increase throughput. In each case, the increase was real. In each case, the cost was a loss of memory I did not notice at the moment I paid it. I only noticed later: when I reached for a note and could not find it in my head, when I reached for a mental model of my own code and it was not there, when I realized the one week I remember from a quarter is the week I was forced to slow down.
Kundera’s equation does not care about the tool. It cares about the tempo. The pen slows the word. The handwritten function slows the program. The unfamiliar protocol slows the project. The units change; the mechanism does not. Time-per-unit-of-thought is what encodes memory. Total time does not matter. You can spend twelve hours in a day and remember none of it, or one hour and remember all of it, and the difference is almost entirely the pace of that hour.
AI is the strongest accelerator we have ever had. Which means it is also, structurally, the strongest forgetter. Not because of anything about AI specifically. Because of Kundera.
The quarter becomes a blur with one vivid week in it. The blur is everything that went fast. The vivid week is the one that refused to.
VI. What if I am just romanticizing friction?#
Honest question. Am I just an aging engineer nostalgic for typewriters?
There is a version of this essay that is exactly that, and I want to name it so I can try not to write it. Not all slowness produces memory. Staring at a stuck compiler for forty minutes is slow and teaches nothing. Filling out a tax form is slow and memorable only as a grievance. Slowness is necessary, not sufficient. What I am really describing is slowness during an act of construction — the building of a sentence, a function, a mental model. That is the slowness that encodes.
There is also a stronger objection: maybe forgetting is fine. I have my version-control log (Jujutsu in my case, with Git compatibility). I have notes. I have the AI itself as a kind of externalized memory I can query on demand. Why does it matter if my biological memory of last quarter’s commits is faint, when the whole history is one search away? Perhaps the future of knowledge work is exactly this — a light, forgetful operator dancing on top of dense externalized systems, recalling only the interfaces.
Maybe. I am genuinely unsure. But I notice, in practice, that the operator who has forgotten the internals makes worse decisions than the operator who has internalized them, and the gap widens when the situation is new. A Jujutsu/Git log tells you what you did. It does not give you why it felt right at the time, what trade-offs you weighed, what the third option was that you rejected. That kind of memory is not in the artifact. It is only in the person who made it, and only if that person was moving slowly enough for it to stick.
Forgetting does not feel like a cost until you need the thing you forgot. Then it feels like a very large cost.
VII. Choosing your own slowness#
If the equation is real, then memory cannot be a default. It has to be a practice. Speed is the ambient condition of modern knowledge work, and without deliberate resistance, the default output is forgetting.
I do not want to be slow at everything. That is not a life — it is paralysis wrapped in virtue. But I want to be slow at some things, deliberately, and I want to know which things. My current rough answers:
Thinking, for me, happens in a notebook. Not because the notebook is magical, but because the pen cannot go faster than my thought, which means I do not get to hide from my thought. When I need to actually decide something — an architecture, a tricky email, what I believe about a problem — pen and paper. Anything else is too fast.
For code, I am still negotiating. My current rule is that I do not let the AI write anything I could not have written myself. If it produces code I do not understand, I rewrite it by hand until I do, or I throw it out. This is slower than the alternative. It is also the only way I stay the author of my own repository rather than its archaeologist.
For learning a new domain, I now assume the AI will make me worse at it if I am not careful. The AI is excellent at shortcuts. Learning is hostile to shortcuts. So when I am entering new territory, I deliberately spend the first few hours without it — the RFC, the primary docs, the diagram on paper, the hand-coded proof of concept — and only bring it in once I have enough structure to push back on what it tells me. Slowness first. Speed after.
None of this is a prescription. Your slow things will be different from mine. The point is only that if you never choose slowness, the modern stack will choose speed for you, every time, at every scale, and you will arrive at the end of your career with a very large body of work and a very small memory of having done any of it. You risk becoming a senior operator whose main advantage is tool fluency (including AI), without a matching increase in deep understanding.
Kundera’s man on the street slowed down without deciding to. His body understood what his mind had not. Ours no longer do. The tools are too smooth. Nothing will slow us down unless we slow ourselves down.
The speed is the forgetting. That is the whole equation. What we do with it is up to us.
Milan Kundera, Slowness, trans. Linda Asher (HarperCollins, 1996), ch. 1. Originally published as La Lenteur, Gallimard, 1995. ↩︎
Van der Meer, A.L.H., & van der Weel, F.R. (2017). “Only Three Fingers Write, but the Whole Brain Works: A High-Density EEG Study Showing Advantages of Drawing Over Typing for Learning.” Frontiers in Psychology, 8, 706. Full text (PMC). ↩︎
Marano, G., Kotzalidis, G.D., Lisci, F.M., et al. (2025). “The Neuroscience Behind Writing: Handwriting vs. Typing—Who Wins the Battle?” Life (Basel), 15(3), 345. Full text (PMC). ↩︎
Baumeister, R.F., Bratslavsky, E., Finkenauer, C., & Vohs, K.D. (2001). “Bad Is Stronger than Good.” Review of General Psychology, 5(4), 323–370. PDF. ↩︎
Comments (Mastodon)
Comment on Mastodon